dataframe의 한 컬럼에 대해 unique한 값을 얻기위해 'datafame['컬럼명'].uique()' 메소드를 사용할 수 있고 결과값이 list가 아닌 ndarray형태로 생성돼죠.
unique() 메소드를 이용하여 생성된 list를 다른 컬럼으로 생성하거나 비교를 위한 list로 활용하려하던 중 ndarray 형태로는 원하는 작업에 지장이 생겨서 list형태로 변환하는 과정입니다.
numpy 형태의 배열의 경우 list와 다르게 ','로 구분이 안되어있습니다.
list형태로 간단하게 변경할 수 있습니다.
import numpy as np
unique_values = df_proceed['시간대별'].unique()
print(unique_values)
print(type(unique_values))
# ndarray to list
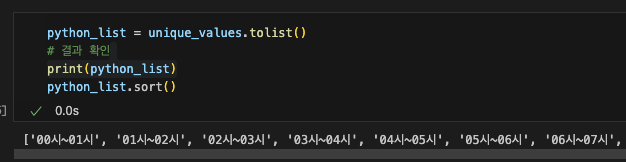
python_list = unique_values.tolist()
# 결과 확인
print(python_list)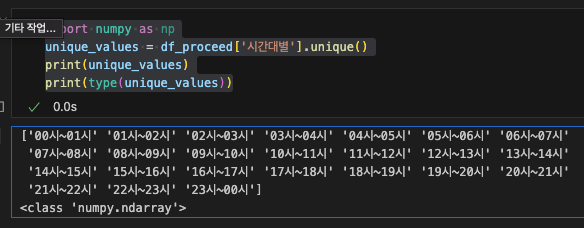
'Programming > Python' 카테고리의 다른 글
| IIS에서 실행중인 flask 서버에 설치된 모듈 확인 (0) | 2024.03.21 |
|---|---|
| flask로 생성한 web service를 docker container에서 실행하니 접속이 안 되는 문제, host='0.0.0.0'의 의미 (0) | 2023.09.13 |
| pytube로 유튜브 영상 or 유튜브 플레이리스트 영상을 모두 다운로드 (0) | 2022.03.22 |